

也能理解外部环境呢,我们首先想到的就是给机器人也安装一对眼睛,是不是就可以和人类一样来理解世界了呢?但是这个过程可比人类复杂的多,本讲我们就来学习机器人中的视觉处理技术。
•机器视觉:用计算机来模拟人的视觉功能,但并不仅仅是人眼的简单延伸,更重要的是具有人脑的一部分功能一一从客观事物的图像中提取信息,进行处理并加以理解,最终用于实际检测、测量和控制;
人类视觉擅长于对复杂、非结构化的场景进行定性解释,但机器视觉凭借速度、精度和可重复性等优势,非常适合对结构化场景进行定量测量。

其中光源用于照明待检测的物体,并突显其特征,便于让相机能够更好的捕捉图像。光源是影响机器视觉系统成像质量的重要因素,好的光源和照明效果对机器视觉判断影响很大。当前,机器视觉的光源已经突破人眼的可见光范围,其光谱范围跨越红外光(IR)、可见光、紫外光(UV)乃至X射线波段,可实现更精细和更广泛的检测范围,以及特殊成像需求。
相机被喻为机器视觉系统的“眼睛”,承担着图像信息采集的重要任务。图像传感器又是相机的核心元器件,主要有CCD和CMOS两种类型,其工作原理是将相机镜头接收到的光学信号转化成数字信号。选择合适的相机是机器视觉系统设计的重要环节,不仅直接决定了采集图像的质量和速度,同时也与整个系统的运行模式相关。
图像处理系统接收到相机传来的数字图像之后,通过各种软件算法进行图像特征提取、特征分析和数据标定,最后进行判断。这是各种视觉算法研究最为集中的部分,从传统的模式识别算法,到当前热门的各种机器学习方法,都是为了更好的让机器理解环境。
对于人来讲,识别某一个物体是苹果似乎理所当然,但是对于机器人来讲,就需要提取各种各样不同种类、颜色、形状的苹果特征,然后训练得到一个苹果的“模型”,再通过这个模型对实时图像做匹配,从而分析面前这个东西到底是不是苹果。
在机器人系统中,视觉识别的结果最终要和机器人的某些行为绑定,也就是第三个部分——控制输出,包含I/O接口、运动控制、可视化显示等。当图像处理系统完成图像分析后,将判断的结果发给机器人控制系统,接下来机器人完成运动控制。比如视觉识别到了抓取目标的位置,通过IO口控制夹爪完成抓取和放置,过程中识别的结果和运动的状态,都可以在上位机中显示,方便我们监控。
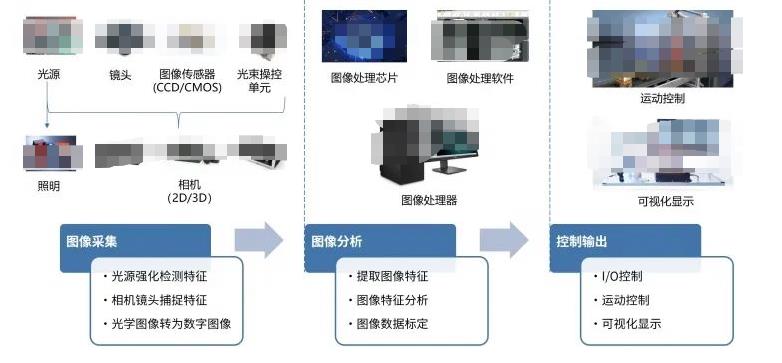
就机器视觉而言,在这三个部分中,图像分析占据了绝对的 核心,涉及的方法、使用的各种开源软件或者框架非常多,我们来了解最为常用的几个。
•推进机器视觉的研究,提供一套开源且优化的基础库,实现了图像处理和计算机视觉方面的很多通用算法;
OpenCV主要使用C/C++语言编写,执行效率较高,致力于真实世界的实时应用。OpenCV实现了图像处理和计算机视觉方面很多通用算法,这样我们在开发视觉应用的时候,就不需要重新去造轮子,而是基于这些基础库,专注自己应用的优化,同时大家的基础平台一致,在知识传播的时候也更加方便,只要你看得懂OpenCV的函数,就可以很快熟悉别人用OpenCV写的代码,大家交流起来非常方便。
和机器人操作系统一样,一款可以快速传播的开源软件,一般都会选择相对开放的许可证,OpenCV主要采用BSD许可证,我们基于OpenCV写的代码,可以对原生库做修改,不用开源,还可以商业化应用。OpenCV目前支持的编程语言也非常多,无论你熟悉哪一种,都可以调用OpenCV快速开始视觉开发,比如C ++,Python,Java、MATLAB等语言,而且还支持Windows,LinuxAndroid和Mac OS等操作系统。
OpenCV中提供的功能非常多,我们在后续的内容中,会给大家介绍一些基础的图像处理方法,大家如果想要深入研究,还可以网上搜索相关的内容。
•Google在2015年发布的机器学习平台,采用数据流图,架构灵活,用于数值计算的开源软件库;
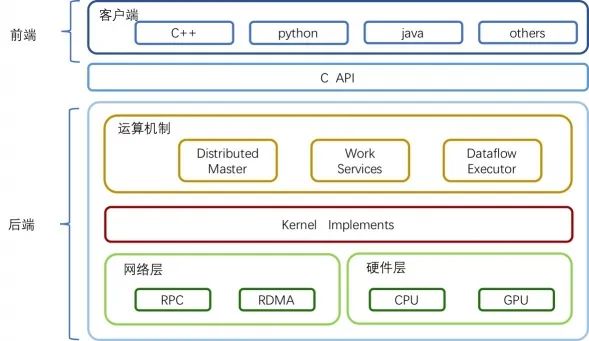
TensorFlow的整体技术框架为两个部分:前端系统提供编程模型,负责构造计算图;后端系统提供运行时环境,负责执行计算图。
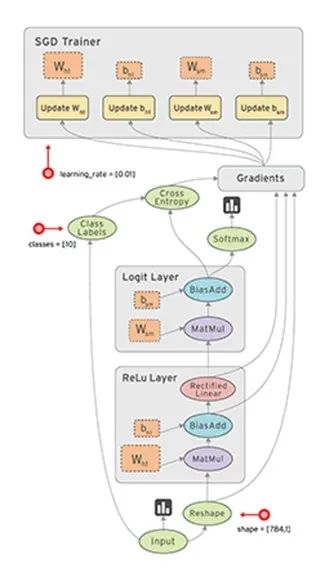
这里的计算图大家应该似曾相识,没错,机器人操作系统ROS的技术框架也是用到了计算图。在TensorFlow的计算图中,数据流是重点,数据在这个图中以张量(tensor)的形式存在,节点在图中表示数学操作,边表示节点间数据的流向。在机器学习的训练过程中,张量——也就是数据,会不断从数据流图中的一个节点流向(flow)另外一个节点,从而完成一系列数算,最终得到结果。这就是TensorFlow名称的由来,正如如图5所示的这张图一样,它生动形象地描述了复杂数据结构在人工神经网中的流动、传输、分析和处理模式。
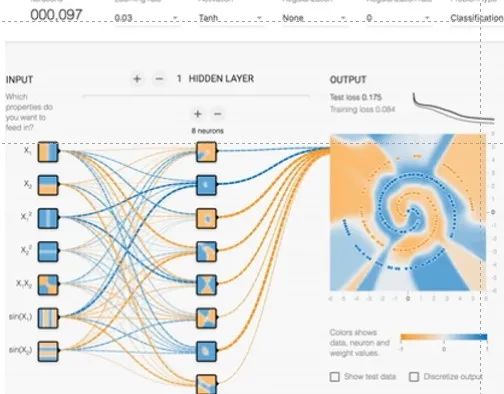
为了便于数据的调试和可视化,TensorFlow还提供了一套可视化工具——TensorBoard,用户可以很容易看到数据流动的每一个部分,同时看到数据训练或者测试的效果。比如如图9-8所示中,经过前边神经网络的计算,蓝色和两种数据被逐渐识别并区分开来。
TensorFlow跨平台性好,可以在Linux、MacOS、Windows、Android等系统下运行,还可以在众多计算机中分布式运行,回想一下多年前战胜人类的围棋AI——AlphaGo,其后台在上万台计算机中、基于TensorFlow搭建的“最强大脑”。
当然,TensorFlow也有不足之处,主要表现在它的代码比较底层,需要用户编写大量的应用代码,而且很多相似的功能,用户还不得不“重新造轮子”。
此外,TensorFlow是Google资深工程师开发而来,使用了不少高深的技术和概念,对于大众开发者来讲,上手学习的门槛就有点高,熟悉的人可以用的炉火纯青,做出很炫酷的效果,不熟悉的人上手就得花费很长时间。对此,TensorFlow官方也提供了一些开源例程和不少训练好的模型,其中之一就是Tensorflow Object Detection API,实现了近年来多种优秀的深度卷积神经网络,可以帮助开发者轻松构建、训练和部署对象检测模型。
如图7所示,前两个是TensorFlow官方例程中的目标检测演示,可以在图片中识别出小狗、人、风筝等目标,在这套开源的框架中,官方还附带了80多种已经训练好的目标模型,包含了我们生活中常见的物品,这两个图片就是使用官方模型识别的效果,比如这里识别到的碗、西兰花,还有这里的杯子、桌子、瓶子等,都可以较为稳定的识别到。不过模型之外的物品就难以识别了。
想要使用这套框架识别其他目标怎么办,没问题,我们可以针对想要识别的目标采样并标注,再放到网络中训练,就可以得到自己的模型库了,接下来就可以完成我们想要的识别任务。比如这里识别两位明星的效果,就是网友使用TensorFlow目标检测方法实现的。
总之Tensorflow Object Detection API,为我们演示了一整套TensorFlow工程应用的流程,按照这个流程,我们就可以快速开发视觉目标检测了。
之前我们有提到过TensorFlow入门门槛较高,除此之外,TensorFlow中的计算图是静态的,也就是说我们要先创建好计算图的结构,然后才能训练,过程中想要改变网络模型是比较困难的。
2017年初,Facebook发布了另外一个开源的机器学习库——PyTorch,虽然底层也是用C++实现的,但是上层主要支持Python。如果用编程语言做一个类比,Tensorflow需要先构建计算图,这就类似C语言,运行之前需要先进行编译,但是可以适配不同的硬件平台,效率较高;而PyTorch类似Python语言,可以动态构建图结构,简单灵活,但是功能的全面性和跨平台性稍差。
除此之外,PyTorch的设计追求最少的封装,尽量符合人类的思维模式,避免重复造轮子,让用户尽可能地专注于实现自己的想法,所思即所得,不需要考虑太多关于框架本身的束缚。不像TensorFlow中张量、图、操作、变量等抽象的概念,PyTorch精简了很多,源码也只有TensorFlow的十分之一左右,更少的抽象、更直观的设计,使得PyTorch的源码十分易于阅读,也更容易进行调试,就像Python代码一样。
总结而言,TensorFlow和PyTorch都是优秀的机器学习开源框架,两者的功能类似,TensorFlow跨平台性能更好,PyTorch灵活易用性更好,两者都有较为广泛的应用,而且作为机器学习的计算平台,两者不仅都可以用于机器视觉识别,还可以用于自然语言理解、运动控制等诸多领域。
回到具体的目标识别。以自动驾驶为例,人们看到图像以后,可以立即识别其中的对象以及所在的位置。这让我们能够在几乎无意识的情况下完成复杂的任务,比如躲避行人。
因此,自动驾驶的训练需要类似水平的反应能力和准确性。这样的系统必须能够分析实时视频中的道路,并且能够在确定路径之前,检测各种类型的对象及其在现实中的位置。
YOLO就是当前最为热门的一种实时目标检测系统,在2015年提出,全称是You only look once,看一眼就能够识别出来,可见实时性对YOLO是至关重要的指标。简单介绍下YOLO的算法流程,它将对象检测重新定义为一个回归问题,运用单个卷积神经网络(CNN) ,将图像分成网格,并预测每个网格的对象概率和边界框。
以一个100x100的图像为例,Yolo的CNN网络将输入的图片分割成7x7的网格,然后每个网格负责去检测那些中心点落在该格子内的目标,比如如图9所示,小狗这个目标的中心点在左下角的网格中,那该网格就负责预测狗这个对象。
每个网格中将有多个边界框,在训练时,我们希望每个对象只有一个边界框,比如最终只有一个边界框把这只狗包起来。因此,我们根据哪个边界框与之前标注的重叠度最高,预测对象的位置和概率。
这样就完成了对目标的实时检测,拿到目标的信息之后,就可以进行后续的机器人行为控制了。YOLO识别的速度非常快,它能够处理实时视频流,比如车辆行驶的动态监测、自然环境中的目标识别,有着非常广泛的应用价值。
以上就是当前较为热门的机器学习和目标检测框架,用于机器视觉的开源软件还有很多,有兴趣可以继续探索补充。
星空全站 上一篇:新手必看!一文看懂流程图中各种图形的含义及用法 下一篇:200多个岗位月薪最高15万
